
Hour of Code – Machine Learning
Estimating students of every age to computer code and programming, the Hour of Code – Machine Learning is a worldwide movement. The Hour of Code – Machine Learning typically sets a one-hour coding activity meant to de-mystify computer programming and enjoy oneself. So, Code.org runs the project, which involves numerous interactive lessons, games, and hands-on activities meant to encourage students to attempt coding. The objective is to promote the learning love of computer science in general and particularly of those groups who have been least served in the field and to promote enjoyment of learning.
Key Features of The Hour of Code – Machine Learning :
- Beginner-Friendly: No prior experience is required; if tutorials guide participants step by step.
- Global Engagement: Over 180 nations have students engaged in the millions.
- Interactive Activities: Capitalizes on such iconic franchise brands as Minecraft, Star Wars, and Frozen.
- Overcoming the Digital Divide: Ensuring access to learn about technology.
What is Machine Learning?
Machine Learning (ML) is an artificial intelligence (AI) branch that makes computers learn from experience and decide on their own without being programmatically instructed. As opposed to predetermined rules, ML algorithms discern data patterns and correlations and help systems become more competent with the passage of time. ML appears across different applications such as image classification, speech recognition, recommender systems, and predictive models.
The fundamental concept of ML is to create models that can generalize from examples instead of memorizing certain instructions. So, These models run on enormous datasets, learn to recognize patterns and make predictions or classifications based on novel, unseen data. Hence, ML has changed industries by automating complex tasks, streamlining efficiency, and enabling better decision-making.
Types of Machine Learning
ML is commonly categorized into three primary categories: Supervised Learning, Unsupervised Learning, and Reinforcement Learning. So, All three have their distinct way of learning from data.
Supervised Learning
The most widely used ML is supervised learning. Through supervised learning, the model gets trained on the labeled dataset so that the input and output values are accompanied with correct outputs. The aim of the model here is to be trained so it learns how input is related to the output to then be able to predict data when new information comes in. So, Some examples of supervised learning are as follows:
<|python_tag|><|start_header_id|>assistant<|end_header_id|>
- Spam Detection: Marking messages if spam or not spam based on labeled examples.
- Image Recognition: Object recognition within images (e.g., dog vs. cat).
- Medical Diagnosis: Foretelling disease based on patient history and symptoms.
Popular Algorithms:
- Linear Regression
- Logistic Regression
- Decision Trees
- Support Vector Machines (SVM)
- Neural Networks
Unsupervised Learning
In unsupervised learning, the model receives unlabeled data and has to identify patterns, structure, or relationships without guidance. Rather than making specific outputs, unsupervised learning is employed for discovering patterns that are hidden or partitioning data into groups.
Examples of Unsupervised Learning:
- Customer Segmentation: Segmentation of customers on the basis of shopping behavior.
- Anomaly Detection: Identifying if abnormal activity or security problems.
- Topic Modeling: Uncovering topics in large text data
Popular Algorithms:
- K-Means Clustering
- Hierarchical Clustering
- Principal Component Analysis (PCA)
- Autoencoders
Reinforcement Learning (RL)
Reinforcement learning is a technique by which an agent is trained to act in such a manner if it can teach itself through the interaction with an environment and is rewarded or penalized for doing anything. Hence, It aims to learn the optimal policy from the cumulative reward.
Examples of Reinforcement Learning:
- AI gaming: AlphaGo and DeepMind’s computer intelligence to play sophisticated games such as chess and Go.
- Robotics: Preparing robots to walk or do something by experimentation.
- Autopilot Cars: Autopilot cars learn how to drive best through experiences with their environments
Popular Techniques:
- Q-Learning
- Deep Q Networks (DQN)
- Policy Gradient Methods
- Actor-Critic Models
Key Concepts in Machine Learning
In order to really comprehend machine learning, some basic concepts need to be understood:
Data
Data is the foundation of ML. It has input features (independent variables) and target values (dependent variables in supervised learning). Quality, diverse, and well-annotated data are essential in order to train correct models.
Types of Data:
- Structured Data: Organized in tables
- Unstructured Data: Text, images, videos, and audio.
- Semi-Structured Data: JSON, XML

Data Preprocessing:
- Cleaning (handling missing values, removing duplicates)
- Normalization/Scaling (bringing values to a standard range)
- Feature Selection (choosing the most relevant attributes)
Models
A model is a mathematical representation of patterns found in data. Therefore, It is trained to make predictions or classifications. So, Different models are used for different types of ML problems.
Examples of Models:
- Decision Trees (for classification)
- Linear Regression (for prediction)
- Neural Networks (for deep learning)
Training
Training is a process by which a model acquires knowledge from data. So, Training entails tuning model parameters to reduce error and increase accuracy.
Training Steps:
- Present training data to the model.
- Optimize model parameters with an optimization algorithm (such as Gradient Descent).
- Reduce errors using loss functions (such as Mean Squared Error, Cross-Entropy Loss).
Evaluation
Evaluation determines how accurately an ML model works on unseen, new data. It indicates if the model is reliable and accurate.
Evaluation Metrics:
- No Accuracy: Compares how many correct predictions are made.
- No Precision & Recall: Best for imbalanced data sets (e.g., detecting fraud).
- No Mean Absolute Error (MAE) & Root Mean Squared Error (RMSE): Applied to regression problems.
Overfitting vs. Underfitting:
- Overfitting: The model overlearns the training data but fails to generalize to new data.
- Underfitting: The model is too simple and fails to capture patterns in the data.
Importance of Learning Machine Learning
Machine learning (ML) is an AI method employed by computers where machines learn and provide predictions without actually being programmed. So, It’s transforming companies along the board, from health and finances to transport and communications. Machine learning is worth learning for individuals and organizations because it helps automate tasks, make informed choices, and resolve complex problems.
Why Learn Machine Learning?
- High Job Market Demand: Corporations need ML specialists to labor on AI work, data analysis, and automatization.
- Increases Analytical Ability: ML improves analyzing ability, and this is desirable in all areas of business.
- Works Automatically: ML decreases effort spent by automatically undertaking monotonous and intricate efforts.
- Better Decision Making: Organizations adopt ML is needed if any anticipating analysis and choice making.
- Technological Advancements: ML stimulates technologies like robotics, autonomous vehicles, disease diagnosis, and others.
Basics of Machine Learning
Machine learning is categorized into three primary types:
Supervised Learning:
- The algorithm learns from labeled data.
- Examples: Spam detection, image classification, medical diagnosis.
Unsupervised Learning:
- The algorithm identifies patterns in unlabeled data.
- Examples: Customer segmentation, anomaly detection, market basket analysis.
Reinforcement Learning:
- The algorithm learns through trial and error, receiving rewards for correct actions.
- Examples: Autonomous vehicles, computer chess, robotic automation.
Key Elements of Machine Learning
- Data: Used as the basis for ML models; the more data, the higher the accuracy.
- Algorithms: Techniques such as decision trees, neural networks, and regression models are employed to learn patterns.
- Training & Testing: Models are trained from data and tested on novel information if any issue in providing precise results.
- Evaluation Metrics: Metrics like precision, recall, and accuracy are employed to assess model performance.
Getting Started with The Hour of Code – Machine Learning .
Hour of Code is an international program that gets individuals, particularly newbies, acquainted with the world of coding within one hour. Hour of Code promotes learning programming for all, irrespective of background.
Select a Platform:
- Go to Hour of Code and pick an activity that suits your level.
- Sites such as Code.org, Scratch, and Khan Academy provide simple exercises for beginners.
Pick a Learning Activity:
- For Kids: Block-based coding using Scratch.
- For Beginners: Simple Python or JavaScript exercises.
- For Advanced Users: AI, robotics, or web development projects.
Follow Step-by-Step Tutorials:
- Most Hour of Code activities come with guided instructions.
- Experiment with small coding exercises before moving to more complex tasks.
Explore Machine Learning with Hour of Code:
- Hour of Code activities also expose users to AI notions, like Google’s Teachable Machine, through which one can train an elementary ML model without coding.
Why Join Hour of Code?
- No Experience Necessary: For complete beginners.
- Fun and Interactive: Game-like and interactive coding activities.
- Short and Efficient: Transfers basic coding principles within an hour.
- Promotes Creativity: Trains the user to think logically and solve puzzles.
Through an introduction to Hour of Code, students can lay a solid base in programming that can eventually take them to learn machine learning and artificial intelligence.
Introduction to a Beginner-Friendly ML Project
Machine Learning (ML) may intimidate beginners at the outset, but beginning with an easy, defined project makes novices grasp salient concepts easily. An ideal beginner ML project involves dealing with a small-sized dataset, subjecting it to basic preprocessing routines, and opting for a minimal model such as linear regression or decision trees. So, The aim here is to pick up hands-on experience in working with data handling, model fitting, and monitoring without overwhelming themselves with complexity.
Step-by-Step Tutorial to Make a Simple Model
- Select a Dataset – Begin with an available dataset, such as the popular Iris dataset or a plain CSV file containing labeled data.
- Preprocess the Data – Clean the dataset by addressing missing values, normalizing numeric data, and encoding categorical features.
- Divide the Data – Divide the data set into train and test sets (e.g., 80% train, 20% test) to effectively test model performance.
- Select a Model – Select a simple model such as linear regression for continuous data or a decision tree for classification.
- Train the Model – Train the model with the training data, tuning hyperparameters if needed.
- Make Predictions – Make predictions using the trained model on the test data.
- Measure Performance – Test the accuracy of the model using parameters as mean squared error (in regression) or accuracy score (in classification).
Testing and Assessing the Model
After an ML model is constructed, it needs to be tested and evaluated on its performance. Therefore, Important steps are:
- Test on a Test Dataset – The model is tested with unseen data in order to evaluate how well the model generalizes.
- Measuring Metrics – Employ metrics such as accuracy, precision, recall, F1-score (if it is classification) or RMSE (if it is regression) to measure.
- Cross-Validation – Data is split multiple times to check the model’s consistency.
- Hyperparameter Tuning – Refining model parameters for better performance.
- Model Comparison – Trying out various models (e.g., logistic regression vs. decision tree) to determine the optimal fit for the data.
Exploring ML Concepts Through Coding
- Python Libraries – Scikit-learn, TensorFlow, and Pandas are libraries that simplify the implementation of ML models.
- Straightforward Script Writing – Making Python scripts to import data, pre-processing the data, training models, and results analysis.
- Experimentation with Multiple Models – Trying out multiple ML models to discover their strengths and weaknesses.
- Data Visualization – Employing Matplotlib and Seaborn in order to create plots that aid in comprehending data patterns.
- Deploying Models – Learning how to save and deploy trained models in actual applications.
Responsible AI Practices
Responsible AI practices are the standards and guidelines that aim to make artificial intelligence systems ethical, transparent, and human values-aligned. Hence, These practices include:
| Key Principle | Description |
| Transparency | Ensure AI models are explainable and understandable. |
| Accountability | Organizations and developers should be responsible for AI outcomes. |
| Privacy & Security | Protect user data and comply with regulations. |
| Inclusivity | Ensure AI is fair and unbiased across diverse groups. |
| Human Oversight | AI should assist, not replace, human decision-making. |
Understanding Datasets and Features
A dataset is a collection of data used to train machine learning models. So, It consists of multiple features, which are individual measurable properties or characteristics of the data. Therefore, features may be numerical (age, salary) or categorical (gender, product type). Hence, Good feature selection and preprocessing are essential in the development of efficient models.
Training and Predictions in a Simple Way
Training entails inputting a dataset into a machine learning model so that it can learn relationships and patterns between target variables and features. The model adapts itself according to the training data. So, after training, the model predicts on unseen, new data. Hence, Accuracy relies on the quality of the training data and the algorithm used.
Visualizing Machine Learning Outcomes
Visualization helps in understanding model performance and insights from the data. So, Common techniques include:
- Scatter plots to see relationships between variables
- Confusion matrices to evaluate classification models
- ROC curves to analyze model sensitivity and specificity
- Feature importance charts to identify key factors influencing predictions.
AI and Ethics in Machine Learning
- Bias and fairness – Preventing models from discrimination.
- Privacy – Safeguarding if user information and transparency
- Accountability – Knowing who is accountable for AI decisions
- Job displacement – Mitigating economic
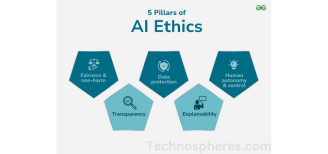
Bias and Fairness in Hour of Code – Machine Learning
Machine learning bias exists when an AI model makes systematically discriminatory decisions based on biases in the data, the algorithms, or societal systems. Fairness seeks to make AI decisions not favor or discriminate against any specific group. Notable concepts include:
- Data Bias: If training data is not representative, AI models can create biased results.
- Algorithmic Fairness: Methods such as re-weighting training examples or adversarial debiasing minimize discrimination.
- Fairness Metrics: Demographic parity and equalized odds are measures that determine if an AI model is treating different groups equally.
- Mitigation Strategies: Approaches like diverse data collection and bias audits help ensure fairness.
Real-World Applications and Ethical Considerations
AI is widely applied in various domains, but ethical concerns must be addressed. Examples include:
| Key Principle | Description |
| Transparency | Ensure AI models are explainable and understandable. |
| Accountability | Organizations and developers should be responsible for AI outcomes. |
| Privacy & Security | Protect user data and comply with regulations. |
| Inclusivity | Ensure AI is fair and unbiased across diverse groups. |
| Human Oversight | AI should assist, not replace, human decision-making. |
To balance ethical issues, organizations need to implement fairness audits, regulatory adherence, and ethical AI development.
Challenges and Fun Exercises
It’s hard to grasp AI ethics and fairness, but fun exercises can be effective:
- Bias Detection Game: Feed an AI model varying inputs and examine its decisions for biases.
- Fairness Tuning Challenge: Tweak model parameters or training data to improve an AI system’s predictions to be fairer.
- Explainability Puzzle: Reverse-engineer the reasons behind an AI decision with the help of interpretability tools given a decision made by an AI.
- Ethical Dilemmas in AI: Provide case studies in which AI created ethical problems and suggest solutions.
- Create a Fair Dataset: Adjust an unbalanced dataset so that it has improved representation from various groups.
Recap of Key Takeaways
A review of the main ideas discussed so far in your machine learning experience. This is usually:
- Knowing the fundamentals of machine learning, supervised, unsupervised, and reinforcement learning.
- Master algorithms like linear regression, decision trees, neural networks, and clustering algorithms.
- How data preprocessing, feature engineering, and model performance metrics as accuracy, precision, recall, and F1-score are important.
- Practical use of machine learning in fields like finance, healthcare, and automation.
Urge to Learn More
- Try applying it on real-world datasets to better understand.
- Engage in competitions such as Kaggle to get hands-on experience.
- Read research papers and maintain current familiarity with AI forums to learn of emerging advancements.
- Study advanced subject areas such as deep learning, NLP, and reinforcement learning.
Subsequent Steps in the Machine Learning Process
Subsequent steps in the Hour of Code – Machine Learning process:
- Developing Coding Competence: Reinforce Python packages like NumPy, Pandas, Scikit-Learn, TensorFlow, and PyTorch.
- Project-Based Work: Construct projects like picture recognition, suggestions systems, or swindle finding.
- Learning Deployment: Get a handle on model deployment using Flask, FastAPI, or cloud platforms like AWS and Google Cloud.
- Studying Advanced Concepts: Look into areas like transfer learning, generative AI, and ethical ramifications of AI. Joining AI Communities: Discuss, go to conferences, and take part in open-source projects.
Read more about Machine Learning from Technospheres.



