
Information Sets Used in Machine Learning
Talking about the Information Sets Used in Machine Learning, information sets refer to the structured or unstructured assemblages of inputs from which models acquire knowledge of patterns or make resolutions. These can involve data points, specific values, labels, and circumstantial or prior earlier knowledge related to a special task. An information set is not just a raw data—it enfolds all the components essential for a machine to gain knowledge, workout, or modify.
Importance of Information Sets Used in Machine Learning
Machine learning completely depends on the calibre, divergent, and integrality of information sets. A model is only as good as the data it is made on. Well-managed data sets help to make sure:
- High model exact values
- Better generalization
- Reduced bias and variation
- Faster schooling and merging
Understanding Information Sets
Definition and Concept
An information set refers to the completeness of input signals and related background that let us know the efficiency of a machine learning model. These are:
- Input features
- Labels or outputs
- Metadata or auxiliary inputs
- Prior knowledge or assumptions
Role in Decision-Making and Learning
In learning, information sets let us:
- Identifying Mathematical relationships between inputs and outputs.
- Estimation of results based on un recorded inputs.
- Selecting actions in reinforcement learning or rule-based systems.
In making decision, especially in changeable or not fixed environments, an information set may show all known variables present to an agent at a given time.
Information Sets vs. Data Sets
Although mostly used interchangeably, the two are conceptually variants:
A data set is generally a set of raw or processed
An information set refers to a structured form of data that’s ready for studying—mostly include preprocessing, contexts, labels, and partitions.

In game theory and decision theory, “Information Sets Used in Machine Learning” also meant to the entire knowledge a decision-maker has at a specific point, which condense into its use in certain ML implications like increased learning.
Types of Information Sets in Machine Learning
Labeled vs. Unlabeled Data
Labeled Data:
Each Example has an affiliated output or type (e.g., spam/not spam). Necessary for supervised schooling.
Unlabeled Data:
No output or response change is attached. Used in unsupervised schooling or as supplementary data in semi-supervised techniques.
Structured vs. Unstructured Information
Structured Data:
Managed into rows and columns, like in spreadsheets or SQL tables. Easy to process with use of proper ML algorithms.
Unstructured Data:
Adding texts, visuals, sounds. Needs specific processing and models like CNNs or transformers.
Feature Sets and Target Variables
Feature Set:
The input variables (predictors) used by the model to make predictions. For example, Age, earning, and location in a customer swirl prediction task.
Target Variable:
The output or dependent variable the model is trained to predict. For example, whether the customer will be confused.
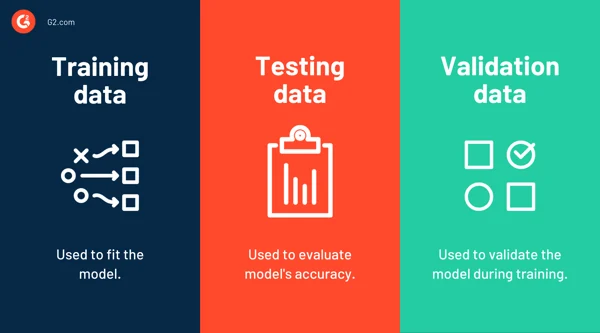
Training, Validation, and Test Sets
Training Set:
The subset of the data used to teach the model by fitting parameters to known inputs and outputs.
Validation Set:
Used to tune hyperparameters and assess the model’s results.
Test Set:
Other than teaching and used only once after model selection, to evaluate final results.
Sources of Information in Machine Learning
Observational Data
Observational data is collected by just recording the statement of a system without getting involved in its procedure. This is the well-known type of data in real-world implications.
Examples:
- Customer browsing attitude on a website
- Patient health over time
- Satellite weather predictions
Experimental Data
Experimental data is collected by controlled tests where one or more variables are slightly changed to see their effect.
Examples:
A/B testing
Clinical trials
Controlled lab measurements
Simulated or Synthetic Data
Simulated data is collected artificially, using statistical models or algorithms to copy real-world application.
Examples:
- Physics simulations
- Autonomous driving scenarios
- GAN-generated
Expert Knowledge and Domain-Specific Inputs
This involves preserved features, regulations derived from niche expertise. While not data in the typical sense, this information can greatly enhance model results.
Examples:
- Rule-based features
- Linguistic annotations
- Engineering constraints
Representation of Information Sets
Tabular Data
Tabular data is the most well-known format mostly getting used in machine learning tasks, where each row showcases an example and each column a feature or quality.
Example of Tabular Data in Credit Scoring
| Customer ID | Age | Income ($) | Credit Score | Defaulted (Target) |
| 001 | 25 | 45,000 | 670 | No |
| 002 | 38 | 85,000 | 740 | No |
| 003 | 52 | 32,000 | 580 | Yes |
Time-Series Data
Time-series data includes observations observed continuously over time. Each data point is time-known, and temporal relationships among data points are important.
Examples:
- Stock prices over days
- Heartbeat signals over seconds
- Power consumption per hour
Image, Text, and Audio Information Sets
These are unprocessed data categories that need special processing:
- Image Data: Pixel arrays
- Text Data: Token sequences, word embeddings, or transformer inputs
- Audio Data: Waveforms, spectrograms, or MFCCs
Graph-Based Information Structures
Graphs are mostly put into function to show nodes and relationships. This structure is good for data where affiliation matter.
Examples:
- Social networks
- Citation networks in academia
- Molecules in drug discovery
Preprocessing and Transformation of Information Sets
Cleaning and Normalization
Un-processed data often have miss-management, missing values, or outliers. Management and normalization prepare data for analysis:
- Removing duplicates, filling in missing values, fixing formats
- Scaling features to a general range
Dimensionality Reduction
High-dimensional data can create overfitting or computational errors. Reduction methods assist reduce the number of characteristics while retaining essential information.
Popular Methods:
- PCA (Principal Component Analysis
- t-SNE and UMAP
- Autoencoders
Information Set Partitioning
Train-Test Split Strategies
This is the basic process of dividing a dataset into other sets:
- Training Set: Used to train the model.
- Test Set: Used to evaluate performance on unseen data.
Typical Ratios:
- 70% train / 30% test
- 80% train / 20% test
The goal is to predict generalization ability. With use of only a training set without a separate test set can lead to mismanaged and misleading performance.
Cross-Validation and K-Folds
Cross-validation is a method to validate models more sturdy:
K-Fold CV: The data is divided into k subsets (folds). The model trains on k–1 folds and validates on the remaining one. This procedure repeats k times.
Example:
- In 5-fold cross-validation, each times appears to validate set exactly for one time.
- It provides a better prediction of model results and reduces variation caused by data partitioning.
Stratified Sampling and Balanced Subsets
When handling with imbalanced data, stratification make sures that each split save the proportion of classes or key subgroups.
Benefits:
- Stable and unbiased validation
- Prevents class skew in experiment distribution
Stratified sampling is especially essential for categorization tasks, where class mis management can be diminished like accuracy or recall.
Role of Information Sets in Different Learning Paradigms
Supervised Learning
Supervised schooling needs titled data—i.e., each input has a known output.
Information Set Components:
- Input features (X)
- Target labels (Y)
Examples:
- Email categorization
- Estimating house prices
Unsupervised Learning
Unsupervised learning hand out with unlabeled data. The algorithm discovers concealed patterns or structures.
Information Set:
- Only input features (X), no labels
Examples:
- Grouping customers by behavior
- Dimensionality reduction (e.g., PCA)
Semi-Supervised and Self-Supervised Learning
- Uses a minute amount of titled data and a larger pool of untitled data.
- Makes pseudo-labels from the data itself. For example, predicting missing words in a sentence.
Reinforcement Learning and State Information Sets
In increase learning (RL), the information set means the condition of the environment an agent can studied and act upon.
- State (s): The current context
- Action (a): What the agent selects
- Reward (r): Feedback after a step
Depending on the observation:
- Fully Observable: The agent observes the entire state
- Partially Observable: The agent only has a side view
Information sets in RL usually develops over time and are affected by past actions and results.
Quality and Relation of Information Sets
Unfairness and Variance Considerations
- Bias means to systematic error from incorrect presupposition in the schooling algorithm.
- Variance refers to model sensitivity to fluctuations in the training data.
Incorrect information sets can worsen both problems. Managing the two is necessary for trustworthy models.
Noise and Redundancy
- Irrelevant or random changes in data, such as mislabeling or sensor issues.
- Redundancy: Repeated or highly related characteristics that exclude new information.
Solutions:
- Noise filtering
- Feature choosing techniques
- Vigorous models
Data Quality Metrics and Measures
To ensure that an information set is usable and influential. Here’s a comparative table:
| Metric | Definition | Why It Matters |
| Completeness | Proportion of non-missing values | Missing data reduces usable information |
| Consistency | Adherence to format and type rules | Inconsistent formats can cause parsing/model errors |
| Uniqueness | Degree of copied entries | Duplicates inflate bias and skew results |
| Accuracy | Correctness of values compared to the facts | Incorrect values can lead to flawed conclusions |
| Timeliness | How current the data is | Outdated data may mislead time-sensitive models |
| Validity | Conformity to acceptable value ranges or rules | Assists in finding anomalies or outliers |
| Relevance | Alignment with the learning objective or purpose | Irrelevant features reduce signal-to-noise ratio |
Legal Considerations
Data Privacy and Consent
Machine learning systems mostly use sensitive personal data. Key errors include:
- Users must be aware how their data is gathered and used.
- Identifiable information must be detached or concealed.
Fairness in Information choice
Information sets can increase existing biases if not selected carefully.
- Using only male patient data for a health model can cause to poor female diagnosis accuracy.
- Racial or economic data may change influence credit scoring models.
Fairness requires:
- Variation and representative sampling
- Bias audits during data collection and giving title
- Methods as fairness constraints in teaching
Dataset Documentation and Provenance
- Data source, collection method, and purpose
- Preprocessing and filtering procedures
- Licensing and usage rights
Case Studies and Applications
Healthcare Diagnosis
ML systems made for medical records, lab experiments, and visualizing data help:
- Foresee disease onset
- Help in diagnostic decision-making
- Prioritizing emergency cases
Natural Language Processing (NLP)
Information sets include:
Text corpora
Labels for categorization
Word implant
Applications:
- Chatbots, sentiment analysis, translation
- Models like BERT, GPT, and T5 trained on great variation text sets
Autonomous Systems
In robotics, drones, and self-driving cars, Information Sets Used in Machine Learning involve:
- Sensor data
- Environmental conditions
- Control feedback loops
Challenges and Future Directions
Limitations of Current Information Sets
Current datasets often face following issues:
- Lack of variance and representation
- Missing contextual or incorrect information
- Static nature
Emerging Data Modalities
Multimodal datasets gather information from multiple categories:
Text + Image (e.g., captions and photos)
Audio + Video
Clinical records + MRI scans

Synthetic and Federated Information Sets
Synthetic Data:
- Generated using GANs
- Useful for privacy-preserving
Federated Learning:
- Models are managed on distributed data
- Preserves privacy and decentralization
Conclusion
Summary of Key Points
- Information Sets Used in Machine Learning are basic to machine learning results and morals.
- They come in many types: managed, unstructured, observational, etc.
- The technique data is divided, cleaned, changed, and used across paradigms deeply affects performance.
- Moral and legal considerations are necessary when dealing reasonable data.
Final Thoughts on the part of Information Sets
As ML develops, so must our approach to data. Making smarter, fairer, and more authentic. AI starts with thoughtfully built and assembled information sets. Making sure quality, openness, and variance in datasets is no longer optional—it’s necessary.
Frequently Asked Questions (FAQs)
Distinguish between an information set and a dataset?
A dataset is a managed collection of data, while an information set have not only raw data but also metadata, context, and any contextual knowledge used by the schooling system.
Why is stratified sampling important in machine learning?
Stratified sampling makes sure that all subgroups are proportionally showed in training sets, preventing unfair validation.
How does synthetic data compare to real-world data?
Synthetic data created to simulate real-world conditions. While it can be helpful for privacy or rare cases, it may lack some unpredictable forms found in original data.
What are multimodal information sets, and why are they essential?
Multimodal information sets gather different data categories. They let the richer understanding and modified results in complex AI tasks like visual question answering.
Read more about Machine Learning on Technospheres.



